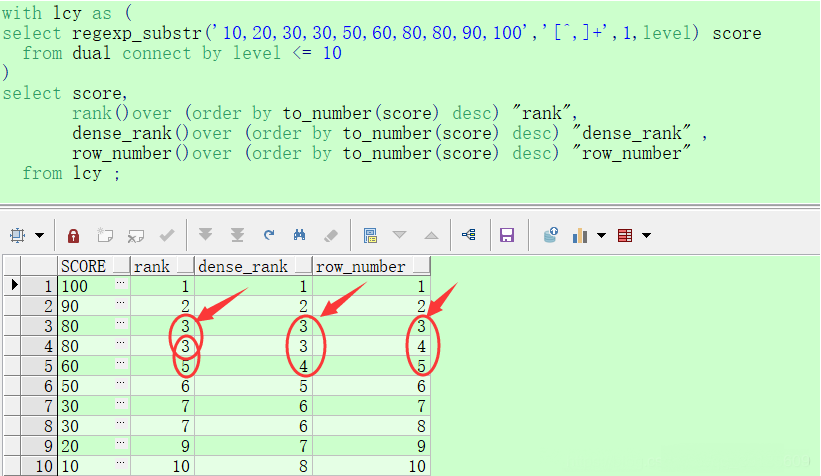
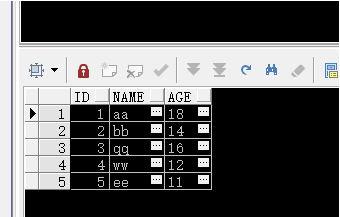
oracle中in����,not in和exists����,not exists之間的區別
2024-08-29 13:53:44
供稿:網友
一直聽到的都是說盡量用exists不要用in����,因為exists只判斷存在而in需要對比值,所以exists比較快����,但看了看網上的一些東西才發現根本不是這么回事。
下面這段是抄的
Select * from T1 where x in ( select y from T2 )
執行的過程相當于:
select *
from t1, ( select distinct y from t2 ) t2
where t1.x = t2.y;
select * from t1 where exists ( select null from t2 where y = x )
執行的過程相當于:
for x in ( select * from t1 )
loop
if ( exists ( select null from t2 where y = x.x )
then
OUTPUT THE RECORD
end if
end loop
從我的角度來說����,in的方式比較直觀����,exists則有些繞,而且in可以用于各種子查詢����,而exists好像只用于關聯子查詢(其他子查詢當然也可以用����,可惜沒意義)����。
由于exists是用loop的方式,所以����,循環的次數對于exists影響最大,所以����,外表要記錄數少����,內表就無所謂了,而in用的是hash join����,所以內表如果小����,整個查詢的范圍都會很小,如果內表很大����,外表如果也很大就很慢了,這時候exists才真正的會快過in的方式����。
下面這段還是抄的
not in 和not exists
如果查詢語句使用了not in 那么內外表都進行全表掃描,沒有用到索引����;
而not extsts 的子查詢依然能用到表上的索引。
所以無論那個表大����,用not exists都比not in要快。
也就是說����,in和exists需要具體情況具體分析,not in和not exists就不用分析了����,盡量用not exists就好了����。
下有一個表-電視劇
TvPlay(title, year, studioname, 男主角, 女主角),
查詢出被重復拍攝1次以上的電視劇名����,(如射雕����,倚天屠龍)
select title
from TvPlay tp
where year >
(select year
from TvPlay
where title = tp.title
);
簡單子查詢只在()中執行一次����,而上面()中的語句是一個關聯子查詢,需要根據外層的條件多次執行����。