c#操作XML(讀XML,寫XML����,更新��,刪除節(jié)點(diǎn),與dataset結(jié)合等)
2024-09-05 20:55:57
供稿:網(wǎng)友
我用的是一種很笨的方法�,但可以幫助初學(xué)者了解訪問xml節(jié)點(diǎn)的過程��。
已知有一個(gè)xml文件(bookstore.xml)如下:
corets���, eva
5.95
1����、插入節(jié)點(diǎn)
往節(jié)點(diǎn)中插入一個(gè)節(jié)點(diǎn):
xmldocument xmldoc=new xmldocument();
xmldoc.load("bookstore.xml");
xmlnode root=xmldoc.selectsinglenode("bookstore");//查找
xmlelement xe1=xmldoc.createelement("book");//創(chuàng)建一個(gè)節(jié)點(diǎn)
xe1.setattribute("genre"��,"李贊紅");//設(shè)置該節(jié)點(diǎn)genre屬性
xe1.setattribute("isbn"�,"2-3631-4");//設(shè)置該節(jié)點(diǎn)isbn屬性
xmlelement xesub1=xmldoc.createelement("title");
xesub1.innertext="cs從入門到精通";//設(shè)置文本節(jié)點(diǎn)
xe1.appendchild(xesub1);//添加到節(jié)點(diǎn)中
xmlelement xesub2=xmldoc.createelement("author");
xesub2.innertext="候捷";
xe1.appendchild(xesub2);
xmlelement xesub3=xmldoc.createelement("price");
xesub3.innertext="58.3";
xe1.appendchild(xesub3);
root.appendchild(xe1);//添加到節(jié)點(diǎn)中
xmldoc.save("bookstore.xml");
結(jié)果為:
corets, eva
5.95
候捷
58.3
2�����、修改節(jié)點(diǎn):
將genre屬性值為“李贊紅“的節(jié)點(diǎn)的genre值改為“update李贊紅”�����,將該節(jié)點(diǎn)的子節(jié)點(diǎn)的文本修改為“亞勝”��。
xmlnodelist nodelist=xmldoc.selectsinglenode("bookstore").childnodes;//獲取bookstore節(jié)點(diǎn)的所有子節(jié)點(diǎn)
foreach(xmlnode xn in nodelist)//遍歷所有子節(jié)點(diǎn)
{
xmlelement xe=(xmlelement)xn;//將子節(jié)點(diǎn)類型轉(zhuǎn)換為xmlelement類型
if(xe.getattribute("genre")=="李贊紅")//如果genre屬性值為“李贊紅”
{
xe.setattribute("genre"����,"update李贊紅");//則修改該屬性為“update李贊紅”
xmlnodelist nls=xe.childnodes;//繼續(xù)獲取xe子節(jié)點(diǎn)的所有子節(jié)點(diǎn)
foreach(xmlnode xn1 in nls)//遍歷
{
xmlelement xe2=(xmlelement)xn1;//轉(zhuǎn)換類型
if(xe2.name=="author")//如果找到
{
xe2.innertext="亞勝";//則修改
break;//找到退出來就可以了
}
}
break;
}
}
xmldoc.save("bookstore.xml");//保存�。
最后結(jié)果為:
corets�����, eva
5.95
亞勝
58.3
3��、刪除節(jié)點(diǎn)
節(jié)點(diǎn)的genre屬性�����,刪除 節(jié)點(diǎn)�。
xmlnodelist xnl=xmldoc.selectsinglenode("bookstore").childnodes;
foreach(xmlnode xn in xnl)
{
xmlelement xe=(xmlelement)xn;
if(xe.getattribute("genre")=="fantasy")
{
xe.removeattribute("genre");//刪除genre屬性
}
else if(xe.getattribute("genre")=="update李贊紅")
{
xe.removeall();//刪除該節(jié)點(diǎn)的全部內(nèi)容
}
}
xmldoc.save("bookstore.xml");
最后結(jié)果為:
corets, eva
5.95
4�、顯示所有數(shù)據(jù)。
xmlnode xn=xmldoc.selectsinglenode("bookstore");
xmlnodelist xnl=xn.childnodes;
foreach(xmlnode xnf in xnl)
{
xmlelement xe=(xmlelement)xnf;
console.writeline(xe.getattribute("genre"));//顯示屬性值
console.writeline(xe.getattribute("isbn"));
xmlnodelist xnf1=xe.childnodes;
foreach(xmlnode xn2 in xnf1)
{
console.writeline(xn2.innertext);//顯示子節(jié)點(diǎn)點(diǎn)文本
}
}
loading...
2005-10-3
一個(gè)通過dataset操作xml的類(源代碼)
using system;
using system.data;
using system.xml;
using system.windows.forms;
//***************************************
// 作者: ∮明天去要飯
// qicq: 305725744
// .net群: 6370988
// http://blog.csdn.net/kgdiwss
//***************************************
namespace ystrp.common
{
///
/// operatexmlbydataset 的摘要說明��。
///
public class operatexmlbydataset
{
public operatexmlbydataset()
{
//
// todo: 在此處添加構(gòu)造函數(shù)邏輯
//
}
#region getdatasetbyxml
///
/// 讀取xml直接返回dataset
///
/// xml文件相對(duì)路徑
///
public static dataset getdatasetbyxml(string strxmlpath)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
if(ds.tables.count > 0)
{
return ds;
}
return null;
}
catch(exception ex)
{
system.windows.forms.messagebox.show(ex.tostring());
return null;
}
}
#endregion
#region getdataviewbyxml
///
/// 讀取xml返回一個(gè)經(jīng)排序或篩選后的dataview
///
///
/// 篩選條件��,如:"name = 'kgdiwss'"
/// 排序條件����,如:"id desc"
///
public static dataview getdataviewbyxml(string strxmlpath���,string strwhere���,string strsort)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
dataview dv = new dataview(ds.tables[0]);
if(strsort != null)
{
dv.sort = strsort;
}
if(strwhere != null)
{
dv.rowfilter = strwhere;
}
return dv;
}
catch(exception)
{
return null;
}
}
#endregion
#region writexmlbydataset
///
/// 向xml文件插入一行數(shù)據(jù)
///
/// xml文件相對(duì)路徑
/// 要插入行的列名數(shù)組�����,如:string[] columns = {"name"��,"ismarried"};
/// 要插入行每列的值數(shù)組���,如:string[] columnvalue={"明天去要飯","false"};
/// 成功返回true����,否則返回false
public static bool writexmlbydataset(string strxmlpath,string[] columns��,string[] columnvalue)
{
try
{
//根據(jù)傳入的xml路徑得到.xsd的路徑��,兩個(gè)文件放在同一個(gè)目錄下
string strxsdpath = strxmlpath.substring(0�,strxmlpath.indexof(".")) + ".xsd";
dataset ds = new dataset();
//讀xml架構(gòu),關(guān)系到列的數(shù)據(jù)類型
ds.readxmlschema(getxmlfullpath(strxsdpath));
ds.readxml(getxmlfullpath(strxmlpath));
datatable dt = ds.tables[0];
//在原來的表格基礎(chǔ)上創(chuàng)建新行
datarow newrow = dt.newrow();
//循環(huán)給一行中的各個(gè)列賦值
for(int i=0; i< columns.length; i++)
{
newrow[columns[i]] = columnvalue[i];
}
dt.rows.add(newrow);
dt.acceptchanges();
ds.acceptchanges();
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
#region updatexmlrow
///
/// 更行符合條件的一條xml記錄
///
/// xml文件路徑
/// 列名數(shù)組
/// 列值數(shù)組
/// 條件列名
/// 條件列值
///
public static bool updatexmlrow(string strxmlpath��,string[] columns,string[] columnvalue�����,string strwherecolumnname�����,string strwherecolumnvalue)
{
try
{
string strxsdpath = strxmlpath.substring(0����,strxmlpath.indexof(".")) + ".xsd";
dataset ds = new dataset();
//讀xml架構(gòu),關(guān)系到列的數(shù)據(jù)類型
ds.readxmlschema(getxmlfullpath(strxsdpath));
ds.readxml(getxmlfullpath(strxmlpath));
//先判斷行數(shù)
if(ds.tables[0].rows.count > 0)
{
for(int i=0; i< ds.tables[0].rows.count; i++)
{
//如果當(dāng)前記錄為符合where條件的記錄
if(ds.tables[0].rows[i][strwherecolumnname].tostring().trim().equals(strwherecolumnvalue))
{
//循環(huán)給找到行的各列賦新值
for(int j=0; j < columns.length; j++)
{
ds.tables[0].rows[i][columns[j]] = columnvalue[j];
}
//更新dataset
ds.acceptchanges();
//重新寫入xml文件
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
}
}
return false;
}
catch(exception)
{
return false;
}
}
#endregion
#region deletexmlrowbyindex
///
/// 通過刪除dataset中ideleterow這一行�,然后重寫xml以實(shí)現(xiàn)刪除指定行
///
///
/// 要?jiǎng)h除的行在dataset中的index值
public static bool deletexmlrowbyindex(string strxmlpath,int ideleterow)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
if(ds.tables[0].rows.count > 0)
{
//刪除符號(hào)條件的行
ds.tables[0].rows[ideleterow].delete();
}
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
#region deletexmlrows
///
/// 刪除strcolumn列中值為columnvalue的行
///
/// xml相對(duì)路徑
/// 列名
/// strcolumn列中值為columnvalue的行均會(huì)被刪除
///
public static bool deletexmlrows(string strxmlpath���,string strcolumn���,string[] columnvalue)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
//先判斷行數(shù)
if(ds.tables[0].rows.count > 0)
{
//判斷行多還是刪除的值多,多的for循環(huán)放在里面
if(columnvalue.length > ds.tables[0].rows.count)
{
for(int i=0; i < ds.tables[0].rows.count; i++)
{
for(int j=0; j < columnvalue.length; j++)
{
if(ds.tables[0].rows[i][strcolumn].tostring().trim().equals(columnvalue[j]))
{
ds.tables[0].rows[i].delete();
}
}
}
}
else
{
for(int j=0; j < columnvalue.length; j++)
{
for(int i=0; i < ds.tables[0].rows.count; i++)
{
if(ds.tables[0].rows[i][strcolumn].tostring().trim().equals(columnvalue[j]))
{
ds.tables[0].rows[i].delete();
}
}
}
}
ds.writexml(getxmlfullpath(strxmlpath));
}
return true;
}
catch(exception)
{
return false;
}
}
#endregion
#region deletexmlallrows
///
/// 刪除所有行
///
/// xml路徑
///
public static bool deletexmlallrows(string strxmlpath)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
//如果記錄條數(shù)大于0
if(ds.tables[0].rows.count > 0)
{
//移除所有記錄
ds.tables[0].rows.clear();
}
//重新寫入����,這時(shí)xml文件中就只剩根節(jié)點(diǎn)了
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
#region getxmlfullpath
///
/// 返回完整路徑
///
/// xml的路徑
///
public static string getxmlfullpath(string strpath)
{
if(strpath.indexof(":") > 0)
{
return strpath;
}
else
{
return application.startuppath + strpath;
}
}
#endregion
}
}
loading...
2005-10-3
一個(gè)通過dataset操作xml的類
這段時(shí)間寫的項(xiàng)目每次都要用到xml保存一些配置,而每次操作xml都覺得挺麻煩����,沒有數(shù)據(jù)庫那么順手。后來發(fā)現(xiàn)用dataset操作xml很方便�,而且靈活性比較好,于是寫了一個(gè)操作xml的類�����,用來應(yīng)付一般的xml操作(源碼下載附件)����。
1 基本思路
其實(shí)用dataset操作xml,歸根到底就是對(duì)dataset里的表格��,行�����,列等進(jìn)行操作���,然后用dataset里的東西重新寫到xml中��,從而實(shí)現(xiàn)編輯xml的目的����。如果再配合上.xsd文件的話,那效果更佳�����。
2 程序詳解
(1) xml文件內(nèi)容
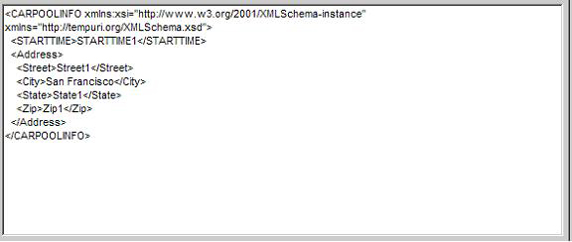
本類操作的xml和生成的xml格式是一樣的����,如下:
http://tempuri.org/xml_xmldb.xsd">
2 asp.net程序員
2
開發(fā)b/s結(jié)構(gòu)程序
asp.net c#等
建國路xxx
2008-8-31
false
4
c#程序員
2
開發(fā)b/s結(jié)構(gòu)程序
asp.net c#等
建國路xxx
2008-8-31
false
然后點(diǎn)擊xml文件右下角的“數(shù)據(jù)”,即可看到熟悉的表格形式�,在表格的任意位置上單擊右鍵選擇“創(chuàng)建架構(gòu)”,將會(huì)生成一個(gè).xsd文件�,該文件用來定義xml各列的類型。其內(nèi)容如下(點(diǎn)擊查看代碼2附件):
http://tempuri.org/xml_xmldb.xsd" xmlns:mstns="http://tempuri.org/xml_xmldb.xsd"xmlns="http://tempuri.org/xml_xmldb.xsd" xmlns:xs="http://www.w3.org/2001/xmlschema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"attributeformdefault="qualified" elementformdefault="qualified"> msdata:locale="zh-cn" msdata:enforceconstaints="false">?msdata:autoincrement="true" msdata:autoincrementstep="1"msdata:autoincrementseed="1" />
注意:如果想像數(shù)據(jù)庫一樣有一個(gè)自動(dòng)增長的id字段���,則可以這樣操作:
首先在xml中添加一個(gè)元素�,這樣生成.xsd的時(shí)候���,就會(huì)有一個(gè)id段���,在.xsd中選中id這一列,在右邊的屬性中����,將“autoincrementseed”和“autoincrementstep”分別設(shè)置為1�,這樣id就會(huì)從1開始以步長為1自動(dòng)增長���。
以上代碼如果看不懂并不要緊����,因?yàn)槲覀兛梢酝ㄟ^dataset來生成這種格式的內(nèi)容��。接下來將開始操作xml�。
(2) 處理xml文件路徑
這里主要是對(duì)傳入的xml路徑進(jìn)行處理�,如果傳入的是相對(duì)路徑,則返回完整路徑����,如果傳入的是完整路徑,則不做處理直接返回�。方法如下:
#region getxmlfullpath
///
/// 返回完整路徑
///
/// xml的路徑
///
public static string getxmlfullpath(string strpath)
{
//如果路徑中含有:符號(hào),則認(rèn)定為傳入的是完整路徑
if(strpath.indexof(":") > 0)
{
return strpath;
}
else
{
//返回完整路徑
return system.web.httpcontext.current.server.mappath(strpath);
}
}
#endregion
(3) 讀取記錄
讀取xml的數(shù)據(jù)到dataset中的方法為:
#region getdatasetbyxml
///
/// 讀取xml直接返回dataset
///
/// xml文件相對(duì)路徑
///
public static dataset getdatasetbyxml(string strxmlpath)
{
try
{
dataset ds = new dataset();
//讀取xml到dataset
ds.readxml(getxmlfullpath(strxmlpath));
if(ds.tables.count > 0)
{
return ds;
}
return null;
}
catch(exception)
{
return null;
}
}
#endregion
以上方法將得到一個(gè)dataset�����,里面保存的是全部xml記錄的信息��,而且沒有經(jīng)過任何處理����。但很多時(shí)候我們需要的只是一些滿足條件的記錄��,這時(shí)需要用以下方法得到:
#region getdataviewbyxml
/// 〈summary〉
/// 讀取xml返回一個(gè)經(jīng)排序或篩選后的dataview
/// 〈/summary〉
/// 〈param name="strxmlpath"〉〈/param〉
/// 〈param name="strwhere"〉篩選條件�����,如:"name = 'kgdiwss'"〈/param〉
/// 〈param name="strsort"〉排序條件����,如:"id desc"〈/param〉
/// 〈returns〉〈/returns〉
public static dataview getdataviewbyxml(string strxmlpath�����,string strwhere����,string strsort)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
//創(chuàng)建dataview來完成排序或篩選操作
dataview dv = new dataview(ds.tables[0]);
if(strsort != null)
{
//對(duì)dataview中的記錄進(jìn)行排序
dv.sort = strsort;
}
if(strwhere != null)
{
//對(duì)dataview中的記錄進(jìn)行篩選,找到我們想要的記錄
dv.rowfilter = strwhere;
}
return dv;
}
catch(exception)
{
return null;
}
}
#endregion
(4) 插入記錄
到現(xiàn)在為止我們已經(jīng)可以隨意讀取xml中的記錄�����,接下來來實(shí)現(xiàn)寫入xml的操作�,方法如下:
#region writexmlbydataset
/// 〈summary〉
/// 向xml文件插入一行數(shù)據(jù)
/// 〈/summary〉
/// 〈param name="strxmlpath"〉xml文件相對(duì)路徑〈/param〉
/// 〈param name="columns"〉要插入行的列名數(shù)組,如:string[] columns = {"name"�,"ismarried"};〈/param〉
/// 〈param name="columnvalue"〉要插入行每列的值數(shù)組��,如:string[] columnvalue={"kgdiwss"����,"false"};〈/param〉
/// 〈returns〉成功返回true��,否則返回false〈/returns〉
public static bool writexmlbydataset(string strxmlpath���,string[] columns,string[] columnvalue)
{
try
{
//根據(jù)傳入的xml路徑得到.xsd的路徑�,兩個(gè)文件放在同一個(gè)目錄下string strxsdpath = strxmlpath.substring(0,strxmlpath.indexof(".")) + ".xsd";
dataset ds = new dataset();
//讀xml架構(gòu)����,關(guān)系到列的數(shù)據(jù)類型
ds.readxmlschema(getxmlfullpath(strxsdpath));
ds.readxml(getxmlfullpath(strxmlpath));
datatable dt = ds.tables[0];
//在原來的表格基礎(chǔ)上創(chuàng)建新行
datarow newrow = dt.newrow();
//循環(huán)給 一行中的各個(gè)列賦值
for(int i=0; i〈 columns.length; i++)
{
newrow[columns[i]] = columnvalue[i];
}
dt.rows.add(newrow);
dt.acceptchanges();
ds.acceptchanges();
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
可能有的朋友不知道怎么用這個(gè)方法插入數(shù)據(jù),在后面我將用實(shí)例介紹�。
(5) 修改記錄
修改記錄的方法要傳入的參數(shù)相對(duì)較多,因?yàn)樾薷挠涗浶枰榷ㄎ坏骄唧w哪一條記錄��,再修改指定列的值�����,以下為修改xml的方法:
#region updatexmlrow
/// 〈summary〉
/// 更行符合條件的一條xml記錄
/// 〈/summary〉
/// 〈param name="strxmlpath"〉xml文件路徑〈/param〉
/// 〈param name="columns"〉列名數(shù)組〈/param〉
/// 〈param name="columnvalue"〉列值數(shù)組〈/param〉
/// 〈param name="strwherecolumnname"〉條件列名〈/param〉
/// 〈param name="strwherecolumnvalue"〉條件列值〈/param〉
/// 〈returns〉〈/returns〉
public static bool updatexmlrow(string strxmlpath�,string[] columns�����,string[] columnvalue�,string strwherecolumnname��,string strwherecolumnvalue)
{
try
{
//同上一方法
string strxsdpath = strxmlpath.substring(0�����,strxmlpath.indexof(".")) + ".xsd";
dataset ds = new dataset();
//讀xml架構(gòu)�����,關(guān)系到列的數(shù)據(jù)類型
ds.readxmlschema(getxmlfullpath(strxsdpath));
ds.readxml(getxmlfullpath(strxmlpath));
//先判斷行數(shù)
if(ds.tables[0].rows.count 〉 0)
{
for(int i=0; i〈 ds.tables[0].rows.count; i++)
{
//如果當(dāng)前記錄為符合where條件的記錄if(ds.tables[0].rows[i][strwherecolumnname].tostring().trim().equals(strwherecolumnvalue))
{
//循環(huán)給找到行的各列賦新值
for(int j=0; j 〈 columns.length; j++)
{
ds.tables[0].rows[i][columns[j]] = columnvalue[j];
}
//更新dataset
ds.acceptchanges();
//重新寫入xml文件
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
}
}
return false;
}
catch(exception)
{
return false;
}
}
#endregion
(6) 刪除記錄
為了方便�,刪除記錄提供了三個(gè)方法,一個(gè)可以刪除所有記錄����,一個(gè)刪除符合條件的行,還有一個(gè)刪除指定index值的行�����,該index值和記錄在data
set中的index值對(duì)應(yīng)��。刪除所有記錄的方法為:
#region deletexmlallrows
/// 〈summary〉
/// 刪除所有行
/// 〈/summary〉
/// 〈param name="strxmlpath"〉xml路徑〈/param〉
/// 〈returns〉〈/returns〉
public static bool deletexmlallrows(string strxmlpath)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
//如果記錄條數(shù)大于0
if(ds.tables[0].rows.count 〉 0)
{
//移除所有記錄
ds.tables[0].rows.clear();
}
//重新寫入,這時(shí)xml文件中就只剩根節(jié)點(diǎn)了
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
刪除指定index值的行的方法為:
#region deletexmlrowbyindex
/// 〈summary〉
/// 通過刪除dataset中ideleterow這一行����,然后重寫xml以實(shí)現(xiàn)刪除指定行
/// 〈/summary〉
/// 〈param name="strxmlpath"〉〈/param〉
/// 〈param name="ideleterow"〉要?jiǎng)h除的行在dataset中的index值〈/param〉
public static bool deletexmlrowbyindex(string strxmlpath,int ideleterow)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
if(ds.tables[0].rows.count 〉 0)
{
//刪除符號(hào)條件的行
ds.tables[0].rows[ideleterow].delete();
}
ds.writexml(getxmlfullpath(strxmlpath));
return true;
}
catch(exception)
{
return false;
}
}
#endregion
這里說一下提供此方法的原因����,有的時(shí)候?qū)ml的內(nèi)容讀到dataset,然后綁定到datagrid后����,由于datagrid中只有一個(gè)模板列,而模板列里又套了表格等許多控件�,這就使得我們可能無法得到記錄對(duì)應(yīng)的id值�����,這個(gè)時(shí)候就可以先得到記錄的index值(第一行為0��,第二行為1����,以此類推),然后將該index值傳到方法中����,就可以將該記錄刪掉�����。
注意:使用該方法的時(shí)候��,綁定到datagrid上的dataset和刪除時(shí)用的dataset要為同一個(gè)�����,也就是說index要相同����,不能有排序��,不然會(huì)誤將記錄�。
有時(shí)候我們需要?jiǎng)h除符合條件的多行,這個(gè)時(shí)候可以用以下方法實(shí)現(xiàn):
#region deletexmlrows
/// 〈summary〉
/// 刪除strcolumn列中值為columnvalue的行
/// 〈/summary〉
/// 〈param name="strxmlpath"〉xml相對(duì)路徑〈/param〉
/// 〈param name="strcolumn"〉列名〈/param〉
/// 〈param name="columnvalue"〉strcolumn列中值為columnvalue的行均會(huì)被刪除〈/param〉
/// 〈returns〉〈/returns〉
public static bool deletexmlrows(string strxmlpath��,string strcolumn��,string[] columnvalue)
{
try
{
dataset ds = new dataset();
ds.readxml(getxmlfullpath(strxmlpath));
//先判斷行數(shù)
if(ds.tables[0].rows.count 〉 0)
{
//判斷行多還是刪除的值多�����,多的for循環(huán)放在里面
if(columnvalue.length 〉 ds.tables[0].rows.count)
{
for(int i=0; i 〈 ds.tables[0].rows.count; i++)
{
for(int j=0; j 〈 columnvalue.length; j++)
{
//找到符合條件的行if(ds.tables[0].rows[i][strcolumn].tostring().trim().equals(columnvalue[j]))
{
//刪除行
ds.tables[0].rows[i].delete();
}
}
}
}
else
{
for(int j=0; j 〈 columnvalue.length; j++)
{
for(int i=0; i 〈 ds.tables[0].rows.count; i++)
{
//找到符合條件的行if(ds.tables[0].rows[i][strcolumn].tostring().trim().equals(columnvalue[j]))
{
//刪除行
ds.tables[0].rows[i].delete();
}
}
}
}
ds.writexml(getxmlfullpath(strxmlpath));
}
return true;
}
catch(exception)
{
return false;
}
}
#endregion
3實(shí)例解析
(7) 讀取xml
以下代碼讀取到一個(gè)沒有排序和篩選的dataset。
datagrid1.datasource = operatexmlbydataset.getdatasetbyxml(@"xml/xml_xmldb.xml");
datagrid1.databind();
以下代碼讀到的數(shù)據(jù)是經(jīng)過篩選和排序的:
datagrid1.datasource = operatexmlbydataset.getdataviewbyxml(
@"xml/xml_xmldb.xml"���, //xml文件路徑
"name = 'asp.net'"�����, //條件:name列值為asp.net
"peoplenum desc"); //按peoplenum列降序排列
datagrid1.databind();
(8) 添加記錄
以下代碼向xml文件中添加了一條記錄�����,同時(shí)給7個(gè)列賦值:
bool b;
b = operatexmlbydataset.writexmlbydataset(
@"xml/xml_xmldb.xml"�����, //xml文件地址
new string[]{
"name"����, //姓名字段
"peoplenum"��, //人數(shù)字段
"address"��, //地址字段
"description"���, //描述字段
"require"��, //需求字段
"deadline"����, //結(jié)束時(shí)間字段
"ismarried" //婚否字段
}���,
new string[]{
"asp.net程序員"����, //姓名字段值
"2"�, //人數(shù)字段值
"建國路", //地址字段值
"b/s結(jié)構(gòu)程序"�, //描述字段值
"asp.net c#等", //需求字段值
datetime.now.toshortdatestring()����, //結(jié)束時(shí)間字段值
"false" //婚否字段值
});
如果b返回值為true,表示添加成功�����,否則表示添加失敗�。以上的寫法我用了些偷懶的方法���,比如我把數(shù)組直接放在參數(shù),而沒有另外申明�,事實(shí)上你可以另外申明一個(gè)數(shù)組,然后再傳到方法中���。
請注意字段在數(shù)組中的位置和值在數(shù)組中的位置的對(duì)應(yīng)關(guān)系�����。
(9) 修改記錄
以下代碼將找到peoplenum列值為3的行����,然后將行的name���、peoplenum�����、�����、description和ismarried四個(gè)字段的值分別更新成kgdiwss、10、描述�、true。
bool b;
b = operatexmlbydataset.updatexmlrow(
@"xml/xml_xmldb.xml"����,
new string[]{"name","peoplenum"��,"description"�,"ismarried"},
new string[]{"kgdiwss"����,"10","描述"�����,"true"}��,
"peoplenum"�����,
"3");
返回true表示修改成功���,否則表示修改失敗��。
請?zhí)貏e注意����,字段類型為邏輯型時(shí),賦值用的是true和false��,而不是0和1�����。
(10) 刪除記錄
以下代碼實(shí)現(xiàn)刪除name列值為數(shù)組中的值的行����。
bool b;
b = operatexmlbydataset.deletexmlrows(
@"xml/xml_xmldb.xml", //xml文件路徑
"name"�, //條件列
new string[]{
"值1", //條件值1
"值2"���, //條件值2
"值3" //條件值3
});
上面代碼執(zhí)行成功后����,name列值為值1�����、值2�����、值3的行將被刪除����。
刪除成功返回true,否則返回false���。
另外兩種刪除的方法用法比較簡單���,這里就不介紹了。
以上就是操作xml的所有方法�����,相信可以滿足很大一部份的使用了���。然而���,如果xml中的數(shù)據(jù)量比較大的話�,使用以上方法效率可能不高����,但話又說回來,如果數(shù)據(jù)量比較大的話�,還是選擇數(shù)據(jù)庫比較好。
中國最大的web開發(fā)資源網(wǎng)站及技術(shù)社區(qū)����,